Article Text

Abstract
Introduction Medication administration errors (MAEs) are the most common type of medication error. Furthermore, they are more common among neonates as compared with adults. MAEs can result in severe patient harm, subsequently causing a significant economic burden to the healthcare system. Targeting and prioritising neonates at high risk of MAEs is crucial in reducing MAEs. To the best of our knowledge, there is no predictive risk score available for the identification of neonates at risk of MAEs. Therefore, this study aims to develop and validate a risk prediction model to identify neonates at risk of MAEs.
Methods and analysis This is a prospective direct observational study that will be conducted in five neonatal intensive care units. A minimum sample size of 820 drug preparations and administrations will be observed. Data including patient characteristics, drug preparation-related and administration-related information and other procedures will be recorded. After each round of observation, the observers will compare his/her observations with the prescriber’s medication order, hospital policies and manufacturer’s recommendations to determine whether MAE has occurred. To ensure reliability, the error identification will be independently performed by two clinical pharmacists after the completion of data collection for all study sites. Any disagreements will be discussed with the research team for consensus. To reduce overfitting and improve the quality of risk predictions, we have prespecified a priori the analytical plan, that is, prespecifying the candidate predictor variables, handling missing data and validation of the developed model. The model’s performance will also be assessed. Finally, various modes of presentation formats such as a simplified scoring tool or web-based electronic risk calculators will be considered.
- Neonatology
Data availability statement
Data sharing not applicable as no datasets generated and/or analysed for this study.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
What is already known on this topic
The aetiology of medication administration errors (MAEs) is multifactorial and complex.
It may be caused by unsafe acts such as slips and lapses, rule-based and knowledge-based mistakes, violations and/or latent conditions such as an error-producing environment due to decisions made by higher organisational levels.
Non-adherence to policies, lack of knowledge, similar look-aike and sound-like medications, lack of nurses and lack of training are among the many factors contributing to MAEs in neonates.
What this study adds
We anticipate that the newly developed model can be used to identify neonates at risk of MAEs, as well as generate estimates of future MAEs among them and the risk factors commonly associated with MAEs.
How this study might affect research, practice or policy
We hope that the information attained from this study will assist policy-makers and stakeholders to conduct timely assessments of MAEs. It can also guide the discussion among stakeholders on the need for the implementation of interventions to prevent MAEs among high-risk neonates.
Introduction
Medication errors (MEs) may arise throughout the medication use process, which consists of prescribing, transcribing, dispensing, administration and monitoring.1 Medication administration errors (MAEs) are the most commonly occurring error as compared with prescribing and dispensing, amounting to more than 50% of all MEs.2 3 Furthermore, MAEs are associated with the highest number of incidents resulting in death and severe harm than other stages of the medication use process. As a result, they contribute to significant economic burden from the utilisation of healthcare services.4 5 It is estimated that approximately 4000 hospitalised patients are harmed by a total of 6 million medication doses administered, costing between US$25 and 35 million annually in the USA.6 A systematic review of all types of MEs reported that the prevalence of MAEs among neonates ranged between 31% and 63% as compared with paediatric and adult patients which ranged between 12.8%–73% and 14.6%–41%, respectively.7
A key aspect of a successful intervention is targeting and prioritising patients at high risk of MEs to improve medication safety.8 Several risk scores have been developed to identify patients at risk of MEs, either among hospitalised adults,9 at admission or during discharge.10 11 Others risk scores specifically identify patients at risk of prescribing errors.12 13 The Automated Medication Error Risk Assessment System (Auto-MERAS)14 was the only developed and validated tool for the prediction of MAEs. However, it was developed and validated among hospitalised adults based on incident reports extracted from the local safety reporting system. Although the use of incident reports to measure MAEs may generate rich information on the causal factors linked to MAEs, it is the least accurate method to measure MAEs as compared with direct observation and chart review.15 16 Apart from that, the use of incident reports meant that major risk factors such as nurses’ workload could not be analysed.14
Given that the prevalence of MAEs among neonates has been reported to be as high as 94.9%,17 a validated model incorporating an extensive list of potential risk factors associated with MAEs would facilitate the healthcare professionals involved in the medication use process to identify at-risk neonates in the neonatal intensive care unit (NICU). To the best of our knowledge, a predictive risk score to identify neonates at risk of MAEs specifically is not yet available. Therefore, this study aims to develop and internally validate a multivariable prediction model for the identification of MAEs among neonates using a prospective direct observational study design. The model will also be externally validated by using data from a different set of neonates. The feasibility of using the risk prediction model for risk stratification will also be evaluated.
Methods
This study will be conducted in accordance with the recommendations for model development and validation.18 19 The study protocol will be reported based on the checklist for multivariable prediction models, namely the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD).20
Study design
A direct observational study for the development of the risk prediction model will be conducted prospectively between April 2022 and April 2023. The subsequent development and validation of the model will be performed until April 2024. The preparation and administration of medications by the nurses are directly observed to detect MAEs. A flowchart of the development, validation and assessment of the risk prediction model is provided in figure 1.
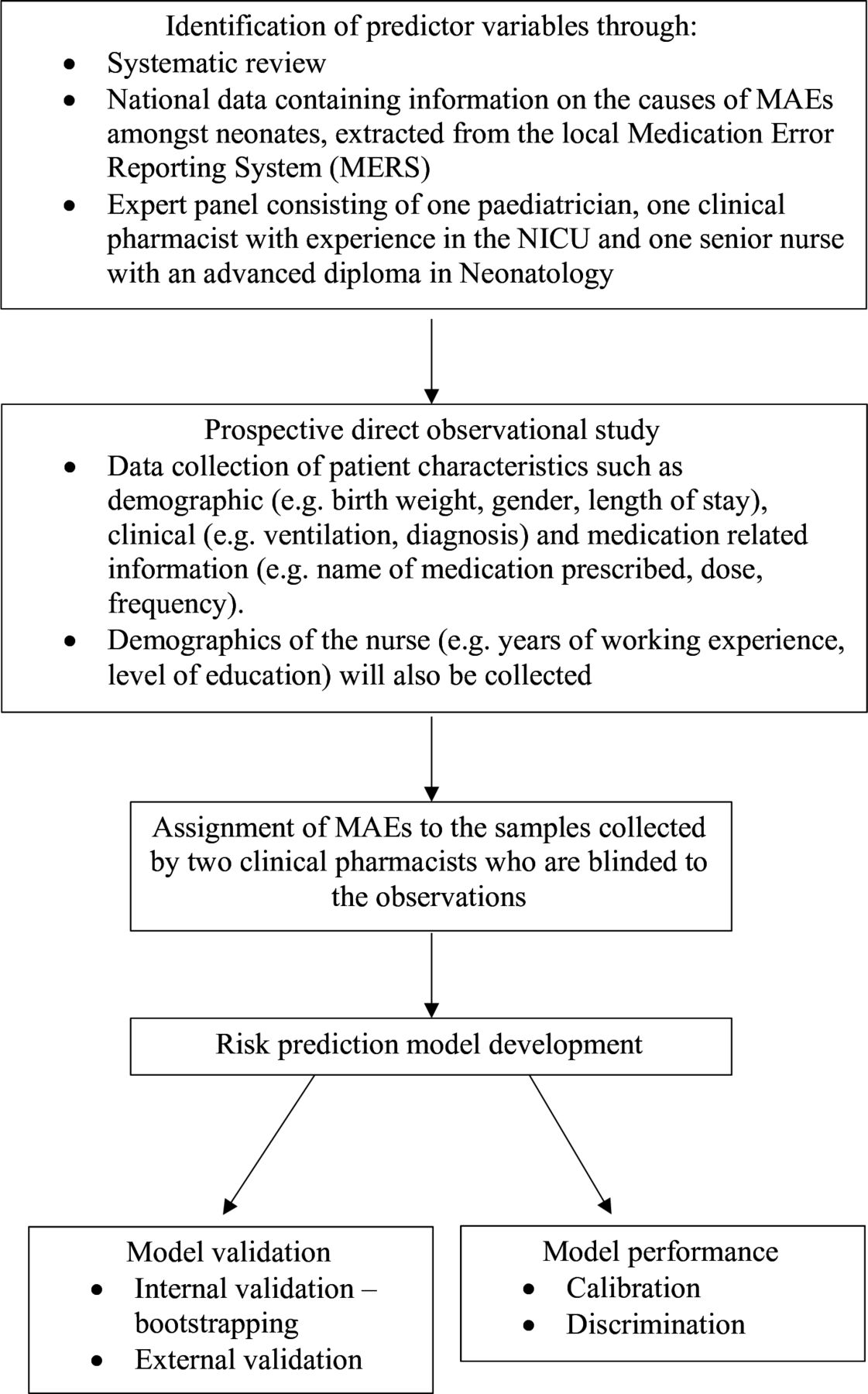
Flowchart of risk prediction model development and validation of medication administration errors (MAEs) in neonates. NICU, neonatal intensive care unit.
Study setting
This national-level multicentre study will include the NICUs of five public hospitals. All hospitals under the Ministry of Health Malaysia (MOH) are classified as state hospitals, major specialist hospitals, minor specialist hospitals or non-specialist hospitals. The subspeciality of neonatology is only available in the state and major specialist hospitals. There are five regions in Malaysia, that is, Northern, Central, Southern, East Coast and East Malaysia. One hospital was chosen from each of these regions. The five selected public hospitals consisting of two state hospitals and three major specialist hospitals were purposively chosen to include both categories of public hospitals providing neonatology subspecialty. The total bed capacity of the NICUs in these five public hospitals ranges from 16 to 38 beds.
Study outcomes
In this study, the outcome of interest is the occurrence of MAEs among neonates. MAE can be defined as any deviations during the preparation and administration of medications when compared with the prescriber’s medication order, hospital policies or the manufacturer’s recommendations in the product leaflet.21 The main intention of this study is to focus on the impact of the outcomes on the system in place instead of the actions of the individual observed. Hence, the above-mentioned definition will be employed as it does not focus on the individual’s actions.
MAEs are further categorised into subcategories according to the stages of preparation and administration (table 1). This will provide a better understanding of the stages where MAEs occur, especially since medication preparation for neonates involves multiple manipulations.22 The definitions of the subcategories of MAEs were adopted from various literature15 21 23 and reviewed by an expert panel consisting of two academicians with at least 20 years of experience and two pharmacists with at least 8 years of experience.
Definitions of the subcategories of MAEs
Data collection
Two clinical pharmacists with at least 10 years of experience will act as observers to conduct the direct observations. Each round of direct observation will be performed by one observer. The observers will be trained beforehand based on the direct observation method of data collection as described by Barker and McConnell.24 They will also be trained to observe and perform practical exercises on the direct observation technique. They are required to complete and pass a written examination (score of at least 80%) consisting of video simulations of drug preparation and administration before they can conduct the observations by themselves. Following that, they will perform pilot observations for 3 days in the ward to familiarise themselves with the procedures in the ward and to reduce the Hawthorne effect. The expected number of medication administrations over 3 days ranges from 80 to 200 medications prescribed. To ensure a uniform understanding of the data collection procedures, all pilot observations will be discussed with the research team. However, these pilot observations will not be included as part of the data for this study.
To reduce the Hawthorne effect on the observed nurses, certain disguises will be taken during data collection.15 The nurses will be informed that the observational study conducted aims to identify the strategies to enhance the medication supply and distribution system as well as to understand the constraints of the nurses’ working environment, rather than assessing their personal practices.25 Written consent will be obtained from the nurses before data collection. Before the observation of the drug preparation and administration, identified candidate predictor variables for the development of the model, information for descriptive analysis of the samples will be collected using a predesigned data collection form, including patient-related information (eg, age, birth weight, gender, length of stay and current diagnosis) and medication-related information for the assignment of error (eg, name of medication prescribed, dose and frequency).
The NICUs of the study sites are usually divided into multiple sections according to the setup of the ward and the severity of the patients. During each round of observation, one section is randomly selected and the nurse(s) involved in the drug preparation and administration in this section will be observed. The observer will closely shadow the nurses who have consented to participate in this study throughout the process. The direct observation will take place during peak medication administration times (07:00–22:00) on weekdays and weekends. During the observation, data related to the preparation of the medication (eg, details of reconstitution and/or dilution such as the time of preparation, expiry, solvent and diluent), administration of the medication (eg, time, rate, route and compatibility) and other procedures (eg, labelling, double-checking of medication administered, interruption and/or distraction) will be recorded.
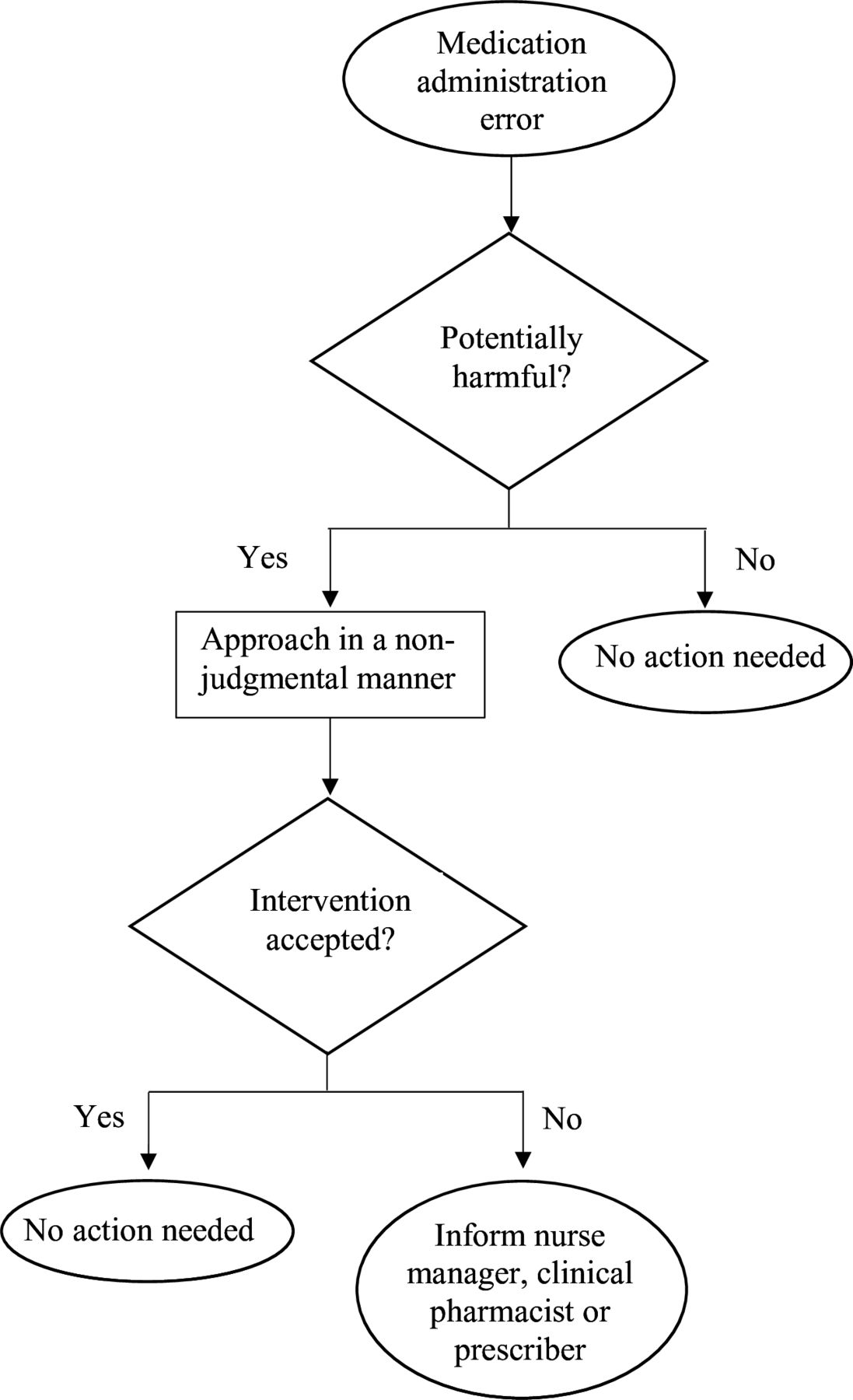
For ethical reasons, the observers will intervene in a non-judgemental manner if a potentially harmful error is about to reach the patient. Examples of MAEs that may be potentially harmful are the administration of a drug that has expired or deteriorated26 and 10-fold overdose.27 In contrast, late in administering doses is not considered to be potentially harmful. In such events, the observers will follow a flowchart that outlines the measures required for an intervention (figure 2).28 However, this error will be included in the dataset as it is assumed that this error will reach the patient if it is not intervened by the observer.

{kind=link}
{kind=link}
Flowchart of measures required when encountering a potentially harmful medication administration error.
After each round of observation, the observer will compare his/her notes with the prescriber’s medication order, hospital policies, manufacturer’s recommendations in the product leaflet and data published in the literature to detect possible MAEs. Demographics of the nurse (eg, years of working experience and level of education) responsible for the preparation and administration of medications will also be recorded. In addition, the clinical pharmacist at each study site will conveniently select and observe 10%29 30 of drug preparations and administrations to ensure the validity and accuracy of the data collected by the observers. The observation will then be compared with the data collected by the observers. All observations by the clinical pharmacist and the observer must be identical for the data to be considered valid and accurate.
Error identification will be independently and individually performed by two clinical pharmacists with at least 6 years of clinical experience. The two clinical pharmacists are not involved in the data collection of the direct observational study. Moreover, they will be performing the assignment of errors to the samples collected separately to avoid influencing each other’s decisions. Disagreements encountered during the assignment of errors to the observed samples will be discussed with the research team to reach a consensus.
Eligibility criteria
Medications prepared and administered by nurses for all routes of administrations will be included while excluded medication administrations are (1) those administered by parents, (2) enteral feedings, parenteral nutrition and blood-derived products, (3) omission of medication administration because patient is not present in the ward during medication administration rounds, (4) omissions due to clinical reasons such as those determined by the nurses (eg, contraindications) and lack of intravenous access, (5) rectal administrations; when neonatal-specific rectal dosage forms are unavailable and the available paediatric rectal dosage form is modified to a lower dose and (6) medical gases and dietary supplements. The same inclusion and exclusion criteria will be applied to the validation cohort.
Data analysis
Predictor variables
To develop a comprehensive method for identifying neonates at risk of MAEs, a total of 15 candidate predictor variables have been identified through the following sources: (1) an extensive systematic review conducted to evaluate the available literature on the factors associated with MAEs among neonates,17 (2) national data containing information on the causes of MAEs among neonates, extracted from the medication error reporting system (MERS) through the MOH Pharmaceutical Services Programme and (3) expert panel. The expert panel consists of a paediatrician with 14 years of clinical experience, a clinical pharmacist with 15 years of clinical experience and a senior nurse with an advanced diploma in Neonatology and 20 years of clinical experience. The expert panel was established to review the predictor variables gathered from the literature review and to identify other important predictor variables based on their clinical experience. Based on the systematic review, MERS and the expert panel, the identified candidate predictor variables are categorised and defined as presented in online supplemental table S1.
Supplemental material
Missing data
Although the predictors included in our data collection are not expected to have a considerable amount of missing data, some will inevitably occur. Hence, strategies to deal with missing data will be determined based on the predictors. Predictors with more than 20% missing data will be excluded.31 Multiple imputations by chained equations will be performed to impute missing values for predictors with data missing at random. For each predictor variable, five multiple imputation datasets will be created to obtain an overall estimate as recommended by Rubin and Schenker.32 Lastly, a sensitivity analysis using the pattern-mixture model approach will be employed to ensure that the data is not missing at random.33
Model development
The two strategies available for the development of a model are the full model and stepwise selection. In our study, the full model approach described by Harrell34 where all identified candidate predictor variables will be included in the model regardless of their association with MAEs or influence on model performance will be conducted. Stepwise selection will then be performed and the results will be compared with the full model. The best model produced by these strategies will then be chosen based on the best fit, the accuracy of the model and the model with the least error.
The categorisation of selected predictor variables into groups will be avoided to minimise the loss of potentially predictive information.35 The frequency distributions for categorical predictor variables will be examined and categories with less than six observations will be combined.34 Since the outcome in our study is categorical, a binary logistic regression will be performed. The regression coefficients will be estimated using maximum likelihood estimation, a probabilistic framework for estimating the model parameters. All the necessary assumptions for regression will be checked. The use of both the full model and stepwise selection is common. However, with the use of real data, certain assumptions such as multicollinearity may not be fulfilled. In instances where such assumptions are not met, the model developed may produce large variations, leading to poor regression coefficient estimates and overfitting.
Overfitting models are models that are too specific for the development sample, making them less generalisable for new but similar individuals. Considering the possibility of having an overfitted model, the least absolute shrinkage and selection operator (LASSO) binary logistic regression will be performed. LASSO is a method that penalises the model coefficients to select predictors and to reduce overfitting during the model-building process.36 37 In LASSO, a first-order penalty function will be constructed to shrink the regression coefficients of the predictor variables to a certain range. A regularisation factor, lambda (λ) will be chosen to maximise the out-of-sample model fit by applying a penalty to shrink the regression coefficients. Predictor variables with a regression coefficient of zero will be removed from the model, leaving behind a panel of optimal variables. Therefore, predictor variables with a weak association with the model will be excluded to ensure that all coefficients are optimised.
Statistical analysis will be performed using Statistical Package for Social Science V.28.0 and R software V.4.2.2 (R Foundation for Statistical Computing, Vienna, Austria).
Model performance
The model’s performance will be evaluated using three measures, namely Brier Score, calibration slope and C-statistic. The Brier Score will be used to assess the overall model performance. It is defined as the average squared of the difference between the observed outcome and the predicted probabilities where a lower Brier Score indicates that the model has a greater predictive accuracy.34 Next, the calibration slope will be used to assess the model calibration. Calibration is an assessment of the agreement between observed outcomes in the data and predicted outcomes of the model. It will be assessed graphically through the inspection of calibration plots. A slope of ‘1’ indicates perfect calibration, a slope of less than ‘1’ indicates overfitting, while a slope of more than ‘1’ indicates underfitting.34 The discriminatory ability of the model, that is, the ability of the model to differentiate between patients at risk and not at risk of MAEs, will be assessed using C-statistic which is derived from the area under the receiver operating characteristic curve. A value of ‘1’ indicates perfect discrimination between patients at risk of MAEs and those who are not at risk while a value of 0.5 indicates that the model cannot discriminate between these two groups of patients.36
Model validation
Internal validation of the prediction model will be assessed using the bootstrapping resampling technique to ensure that the prediction models are reproducible. This will provide insight as to whether the model is potentially too optimistic or overfitted.38 Bootstrap samples using at least 500 bootstrap resampling procedures will be drawn. The difference in the discrimination and calibration between each bootstrap model and the original model developed will be averaged out to adjust for optimism.36 Bootstrapping also provides a shrinkage factor that allows the adjustment of the estimated regression coefficients in the final model. A global shrinkage factor of >0.9 is desired.34 The external validation of the new risk prediction model will be conducted to demonstrate its predictive value. It will be conducted prospectively among new patients who are similar to those recruited for the development of the risk prediction model. The predictive performance based on the same measures of discrimination and calibration used in the internal validation will be reported.
Model presentation
The final model will be presented for both the derivation and validation samples. As predictions are the main interest, the full prediction model that consist of the regression coefficients and the model intercept will be published. Various modes of presentation formats such as a simplified scoring tool or web-based electronic risk calculators will be considered.
Sample size
Sample size calculations following the four criteria for binary outcomes as recommended by Riley et al are performed to minimise overfitting of the model and to ensure that precise predictions of the developed model.39 We have specified the anticipated outcome proportion as 0.31,40 a total number of candidate predictors of 15, a global shrinkage factor of 0.9 and the anticipated model performance as 0.15 as defined by Cox-Snell R2.39 Taking these criteria into consideration, the minimum sample size required to ensure all criteria are fulfilled is 820 drug administrations. Each sample of drug administration is considered an independent sample even if it is prepared and administered by the same nurse as the factors leading to an MAE may be different. The number of drug administrations to be observed in the study sites will be allocated proportionally to the number of expected admissions in each hospital.
Data availability statement
Data sharing not applicable as no datasets generated and/or analysed for this study.
Ethics statements
Patient consent for publication
Ethics approval
This study involves human participants and was approved by Medical Research and Ethics Committee, Ministry of Health Malaysia (NMRR-21-1484-59494 (IIR)) on 24 January 2022 and Medical Ethics Committee, Universiti Kebangsaan Malaysia on 10 February 2022. Participants gave informed consent to participate in the study before taking part.
Acknowledgments
We would like to thank the director general of Health Malaysia for his permission to publish this article. We would like to thank Dr Lee Khai Yin, Dr Nazedah Binti Ain @ Ibrahim and Thun Yen Kheng for their contribution to this study as the expert panel as well as all the nurses for their participation in this study.
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Contributors JHB, NMS, AMA, NAMT and CMP conceptualised the study. JHB and ZS designed the statistical plan for this study, which was reviewed by all authors. JHB drafted the manuscript and all authors reviewed the manuscript. All authors read, contributed and approved the final version of the manuscript.
Funding This work is supported by the Fundamental Research Grants Scheme by the Ministry of Higher Education of Malaysia (FRGS/1/2022/SKK16/UK/02/7).
Competing interests N/A.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.